|
1U with Grace Hopper |
1U with Grace Hopper LC |
1U 2-Node with Grace Hopper |
1U 2-Node with Grace CPU |
2U with Grace CPU |
2U with X86 DP |
|
 |
 |
 |
 |
 |
 |
| Model |
ARS-111GL-NHR |
ARS-111GL-NHR-LCC |
ARS-111GL-DNHR-LCC |
ARS-121L-DNR |
ARS-221GL-NR |
SYS-221GE-NR |
| CPU |
72-core Grace Arm Neoverse V2 CPU + H100 Tensor Core GPU in a single chip |
72-core Grace Arm Neoverse V2 CPU + H100 Tensor Core GPU in a single chip |
72-core Grace Arm Neoverse V2 CPU + H100 Tensor Core GPU in a single chip per node |
144-core Grace Arm Neoverse V2 CPU + H100 Tensor Core GPU in a single chip per node (total of 288 cores in one system |
144-core Grace Arm Neoverse V2 CPU + H100 Tensor Core GPU in a single chip |
4th or 5th Generation Intel Xeon Scalable Processors |
| Cooling |
Air-cooled |
Liquid-cooled |
Liquid-cooled |
Air-cooled |
Air-cooled |
Air-cooled |
| GPU Support |
NVIDIA H100 Tensor Core GPU with 96GB of HBM3 |
NVIDIA H100 Tensor Core GPU with 96GB of HBM3 |
NVIDIA H100 Tensor Core GPU with 96GB of HBM3 per node |
Please contact for possible configurations |
Up to 4 double-width GPUs including NVIDIA H100 PCIe, H100 NVL, L40S |
Up to 4 double-width GPUs including NVIDIA H100 PCIe, H100 NVL, L40S |
| Memory |
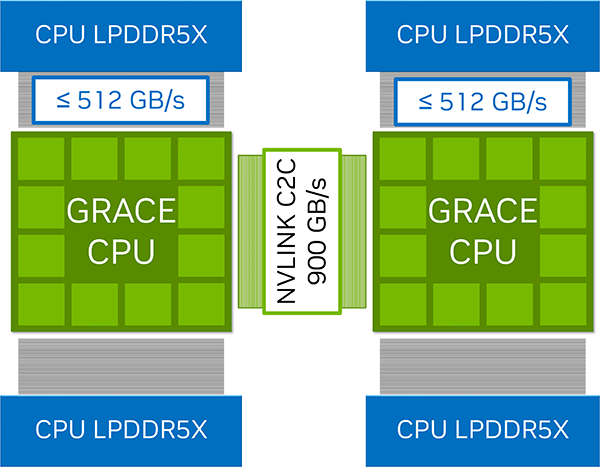
CPU: 480G integrated LPDDR5X with ECC
GPU: 96GB HBM3 |
CPU: 480G integrated LPDDR5X with ECC
GPU: 96GB HBM3 |
CPU: 480G integrated LPDDR5X with ECC per node
GPU: 96GB HBM3 per node |
Up to 480GB of integrated LPDDR5X with ECC and up to 1TB/s of memory bandwidth per node |
Up to 480GB of integrated LPDDR5X with ECC and up to 1TB/s of memory bandwidth per node |
Up to 2TB, 32x DIMM Slots, ECC DDR5-4800 DIMM |
| Networking |
3x PCIe 5.0 x16 slots supporting NVIDIA Bluefield-3 or ConnectX-7 |
3x PCIe 5.0 x16 slots supporting NVIDIA Bluefield-3 or ConnectX-7 |
2x PCIe 5.0 x16 slots per node supporting NVIDIA Bluefield-3 or ConnectX-7 |
3x PCIe 5.0 x16 slots per node supporting NVIDIA Bluefield-3 or ConnectX-7 |
3x PCIe 5.0 x16 slots supporting NVIDIA Bluefield-3 or ConnectX-7 |
3x PCIe 5.0 x16 slots supporting NVIDIA Bluefield-3 or ConnectX-7 |
| Storage |
8x Hot-swap E1.S drives & 2x M.2 NVMe drives |
8x Hot-swap E1.S drives & 2x M.2 NVMe drives |
4x Hot-swap E1.S drives & 2x M.2 NVMe drives per node |
4x Hot-swap E1.S drives & 2x M.2 NVMe drives per node |
8x Hot-swap E1.S drives & 2x M.2 NVMe drives |
8x Hot-swap E1.S drives & 2x M.2 NVMe drives |
| Power Supplies |
2x 2000W Titanium Level |
2x 2000W Titanium Level |
2x 2700W Titanium Level |
2x 2700W Titanium Level |
3x 2000W Titanium Level |
3x 2000W Titanium Level |
|
Configure Now |
Configure Now |
Configure Now |
Configure Now |
Configure Now |
Configure Now |



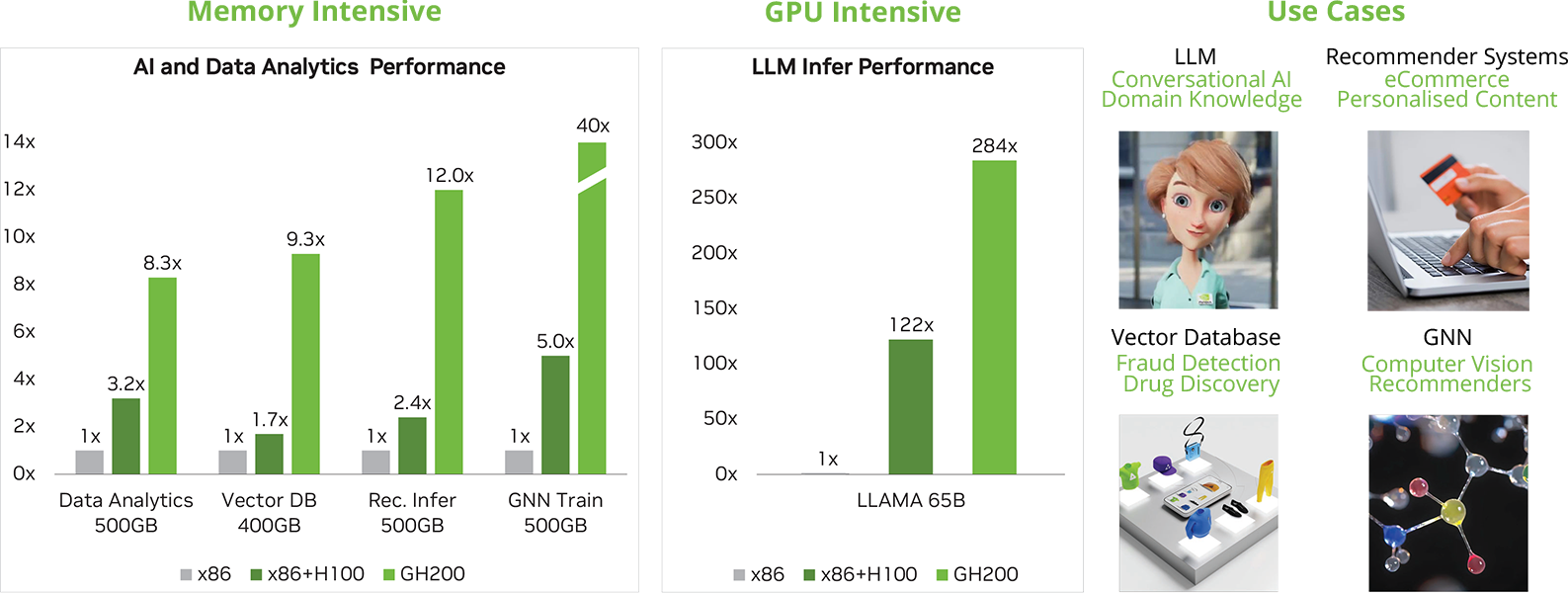


 Our Rigorous Testing
Our Rigorous Testing Un-Equaled Flexibility
Un-Equaled Flexibility


 Call Our UK Sales Team Now
Call Our UK Sales Team Now