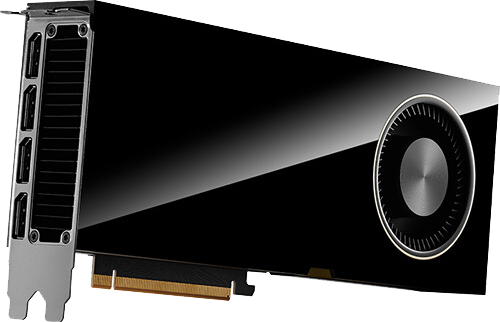
The NVIDIA L4 Tensor Core GPU, built on the NVIDIA Ada Lovelace architecture, offers versatile and power-efficient acceleration across a wide range of applications, including video processing, AI, visual computing, graphics, virtualisation, and more. Available in a compact low-profile design, the L4 provides a cost-effective and energy-efficient solution, ensuring high throughput and minimal latency in servers spanning from edge devices to data centers and the cloud.

Accelerate Workloads Efficiently and Sustainably
The NVIDIA L4 is an integral part of the NVIDIA data center platform. Engineered to support a wide range of applications such as AI, video processing, virtual workstations, graphics rendering, simulations, data science, and data analytics, this platform enhances the performance of more than 3,000 applications. It is accessible across various environments, spanning from data centers to edge computing to the cloud, offering substantial performance improvements and energy-efficient capabilities.
As AI and video technologies become more widespread, there's a growing need for efficient and affordable computing. NVIDIA L4 Tensor Core GPUs offer a substantial boost in AI video performance, up to 120 times better, resulting in a remarkable 99 percent improvement in energy efficiency and lower overall ownership costs when compared to traditional CPU-based systems. This enables businesses to reduce their server space requirements and significantly decrease their environmental impact, all while expanding their data centers to serve more users. Switching from CPUs to NVIDIA L4 GPUs in a 2-megawatt data center can save enough energy to power over 2,000 homes for a year or offset the carbon emissions equivalent to planting 172,000 trees over a decade.
Enterprise Ready: AI Software Streamlines Development and Deployment
As AI becomes commonplace in enterprises, organizations need comprehensive AI-ready infrastructure to prepare for the future. NVIDIA AI Enterprise is a complete cloud-native package of AI and data analytics software, designed to empower all organizations in excelling at AI. It's certified for deployment across various environments, including enterprise data centers and the cloud, and includes global enterprise support to ensure successful AI projects.
NVIDIA AI Enterprise is optimised to streamline AI development and deployment. It comes with tested open-source containers and frameworks, certified to work on standard data center hardware and popular NVIDIA-Certified Systems equipped with NVIDIA L4 Tensor Core GPUs. Plus, it includes support, providing organizations with the benefits of open source transparency and the reliability of global NVIDIA Enterprise Support, offering expertise for both AI practitioners and IT administrators.
NVIDIA AI Enterprise software is an extra license for NVIDIA L4 Tensor Core GPUs, making high-performance AI available to almost any organization for training, inference, and data science tasks. When combined with NVIDIA L4, it simplifies creating an AI-ready platform, speeds up AI development and deployment, and provides the performance, security, and scalability needed to gain insights quickly and realize business benefits sooner.



































 Artificial Intelligence Server for HMRC Fraud Detection
Artificial Intelligence Server for HMRC Fraud Detection  Ultra-Performance AI Server for Samsung
Ultra-Performance AI Server for Samsung 
 Our Rigorous Testing
Our Rigorous Testing Un-Equaled Flexibility
Un-Equaled Flexibility


 Call Our UK Sales Team Now
Call Our UK Sales Team Now