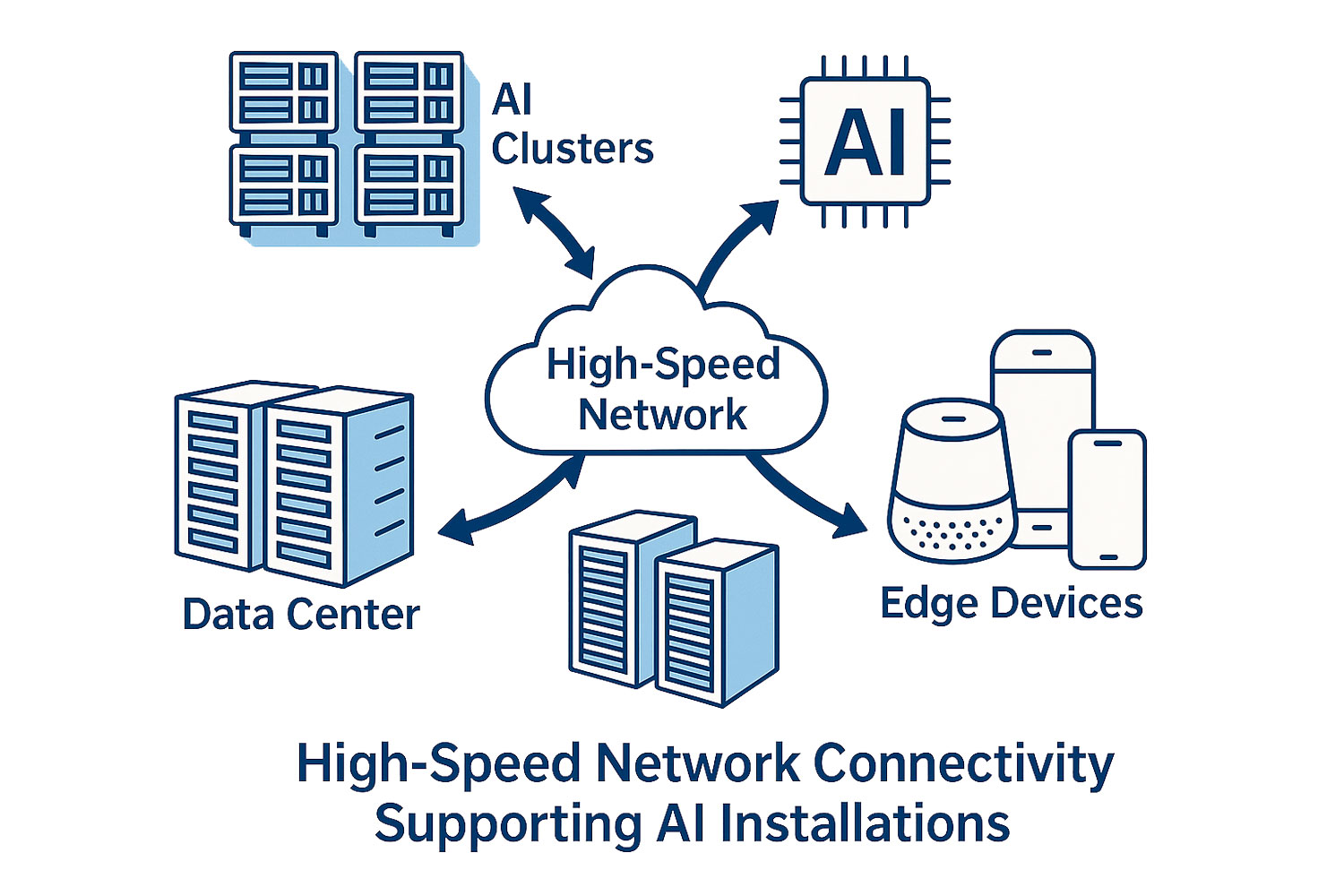
AI networking refers to the high-performance interconnects and network architectures that enable communication between GPUs, servers, storage systems, and edge environments.
Unlike traditional enterprise networking, AI networking must support:
- High-bandwidth data movement
- Ultra-low latency communication
- Distributed GPU workloads
- Parallel processing across clusters
- Scalable inter-node communication
Performance depends on how compute, storage, and networking operate together as a unified system. When networking becomes a bottleneck, even the most powerful GPUs and accelerators cannot operate at peak efficiency.
Why does networking matter for AI workloads?
AI workloads rely on rapid data movement between GPUs, storage systems, and compute nodes. Poor network performance can leave GPUs waiting for data or communication between nodes, slowing AI training and inference workloads.
What is the difference between AI networking and traditional enterprise networking?
AI networking prioritises low latency, high throughput, and distributed communication between systems, while traditional enterprise networking is typically designed for transactional business applications.
What causes networking bottlenecks in AI environments?
Common bottlenecks include insufficient bandwidth, network congestion, slow inter-node communication, and poor scaling across distributed GPU environments.
What is InfiniBand used for?
InfiniBand is commonly used in AI training and HPC environments that require ultra-low latency, high bandwidth, and fast communication between GPU clusters and compute nodes.
What networking is required for AI training?
AI training environments typically require high-bandwidth, low-latency networking capable of supporting distributed GPU communication, parallel processing, and fast data movement between compute and storage systems.
Can networking limit GPU performance?
Yes. Insufficient bandwidth or high network latency can leave GPUs waiting for data or communication between nodes, reducing overall training efficiency and system performance.
What is network latency?
Network latency refers to the time it takes for data to travel between systems or nodes. Low latency is critical for distributed AI workloads that rely on constant communication between GPUs and servers.
What is the difference between NVLink and InfiniBand?
NVLink is a high-speed GPU-to-GPU interconnect used within tightly coupled systems, while InfiniBand is a network fabric designed for communication across multiple servers and distributed AI clusters.
How much bandwidth does AI training require?
Bandwidth requirements depend on model size, dataset scale, and the number of GPUs involved. Large-scale AI training environments often require 100GbE, 200GbE, 400GbE, or InfiniBand networking.
When should AI networking scale out?
AI networking should scale out when GPU clusters, datasets, or distributed workloads grow beyond the capabilities of a single system or network fabric.
What is the role of networking in an AI factory?
Networking connects GPUs, storage, and compute resources across the AI factory, enabling high-speed data movement, distributed training, and efficient scaling of AI workloads.
Should AI networking run on Ethernet or InfiniBand?
The right choice depends on workload requirements, performance goals, scalability needs, and budget. InfiniBand is commonly used for large-scale AI training and HPC environments, while Ethernet is often used for more flexible or mixed infrastructure deployments.
Broadberry works with customers to evaluate these trade-offs and determine the most appropriate networking architecture for their AI environment.
















 Our Rigorous Testing
Our Rigorous Testing Un-Equaled Flexibility
Un-Equaled Flexibility


 Call Our UK Sales Team Now
Call Our UK Sales Team Now